引言
限流是当服务负载(或 Qps)超过一定量级(Load)时,主动丢弃一部分请求,是保护服务路径核心系统不被拖垮的常用方案。是服务端常用的一种过载保护的手段。
系统的最大吞吐量(重要)
下面这段文字解释了maxFlight的计算逻辑:什么时候系统的吞吐量就是最大的吞吐量?
-
首先我们可以通过统计过去一段时间的数据,获取到平均每秒的请求量 QPS,以及请求的耗时时间,为了避免出现前面 900ms 一个请求都没有最后 100ms 请求特别多的情况,使用滑动窗口算法来进行统计
-
一般的方法是从系统启动开始,就把这些值给保存下来,然后计算一个吞吐的最大值,用这个来表示我们的最大吞吐量就可以了。但是这样存在一个问题是,我们很多系统其实都不是独占一台机器的,一个物理机上面往往有很多服务,并且一般还存在一些超卖,所以可能第一个小时最大处理能力是 100,但是这台节点上其他服务实例同时都在抢占资源的时候,这个处理能力最多就只能到 80 了
-
所以,需要一个数据来做启发阈值,只要这个指标达到了阈值那我们就进入流控当中。常见的选择一般是 CPU、Memory、System Load,Kratos这里采用的是CPU(80%),即 CPU 负载超过 80% 的时候,获取过去 5s 的最大吞吐数据(假设滑动窗口的单位是100ms,那么需要统计5s/100ms=50个窗口的值),然后再统计当前系统中的请求数量,只要当前系统中的请求数大于最大吞吐那么我们就丢弃这个请求。
传统限流方式
之前文章中介绍过,传统的限流算法,如漏桶、令牌桶等,他们的缺点是单一限流和无差别限流。此外,系统需要先做压测,拿到一个初始的限流参考值,超过这个值才启动限流机制。
自适应限流保护
而 BBR 限流的思路 和传统方式有很大区别:
TCP BBR 拥塞控制算法 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。
简言之,自适应限流就是根据当前负载情况,来嗅探 load 的值,尽可能提高系统的吞吐量。
自适应限流算法原理
本篇引用自 alibaba/Sentinel 项目的文档:
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合 应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数 等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
背景
在开始之前,我们先了解一下系统保护的目的:
- 保证系统不被拖垮
- 在系统稳定的前提下,保持系统的吞吐量
长期以来,系统保护的思路是根据硬指标,即系统的负载(load1)来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。这个思路给我们带来了不可避免的两个问题:
- load 是一个 “结果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
- 恢复慢。想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高。
TCP BBR 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值 。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。
Sentinel 在系统自适应保护的做法是, 用 load1 作为启动自适应保护的因子,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的, 而不是资源维度的,并且仅对入口流量生效 。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的 maxQps * minRt 估算得出。设定参考值一般是 CPU cores * 2.5。
- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
原理
我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候, 请求不需要排队,直接从水管中穿过,这个请求的 RT 是最短的 ;反之, 当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间 。
- 推论一: 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。 我们用 T 来表示(水管内部的水量),用 RT 来表示请求的处理时间,用 P 来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P ∗ RT 个请求。换一句话来说,当 T≈QPS∗Avg(RT) 的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT 会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
- 推论二: 当保持入口的流量是水管出来的流量的最大的值的时候,可以最大利用水管的处理能力。
然而,和 TCP BBR 的不一样的地方在于,还需要用一个系统负载的值(load1)来激发这套机制启动。
注:这种系统自适应算法对于低 load 的请求,它的效果是一个 "兜底" 的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
Kraots 的限流算法
kratos 借鉴了 Sentinel 项目的自适应限流系统,通过综合分析服务的 cpu 使用率、请求成功的 qps 和请求成功的 rt(请求成功的响应耗时) 来做自适应限流保护。从官方文档上看,限流算法要实现的核心目标有如下两点:
- 自动 嗅探负载和 qps,减少人工配置 && 干预
- 削顶,保证超载时系统不被拖垮,并能以高水位 qps 继续运行
BBR 限流规则依靠下面 4 个指标共同确定:
| 指标名称 | 指标含义 |
|---|---|
| cpu | 最近 1s 的 CPU 使用率均值,使用滑动窗口平均计算,采样周期是 250ms |
| inflight | 当前处理中正在处理的请求数量 |
| pass | 请求处理成功的量 |
| rt | 请求成功的响应耗时 |
滑动窗口
在自适应限流保护中,采集到的指标的时效性非常强,系统只需要采集最近一小段时间内的 qps、rt 即可,对于较老的数据,会自动丢弃。为了实现这个效果,kratos 使用了滑动窗口来保存采样数据。
整个滑动窗口用来保存最近 1s 的采样数据,每个小的桶用来保存 500ms 的采样数据。 当时间流动之后,过期的桶会自动被新桶的数据覆盖掉,在图中,在 1000-1500ms 时,bucket 1 的数据因为过期而被丢弃,之后 bucket 3 的数据填到了窗口的头部。
限流公式(核心!)
在 Kratos 的限流算法中,判断是否丢弃当前请求的算法如下:
( cpu > 800 OR (Now − PrevDrop) < 1s ) AND ( MaxPass ∗ MinRt ∗ windows / 1000 < InFlight )
各部分解释:
- cpu > 800:表示 CPU 负载大于 80% 进入限流
- (Now - PrevDrop) < 1s:表示只要触发过限流(1 次),那么在 1s 内都会去做限流的判定,这是为了避免反复出现限流恢复导致请求时间和系统负载产生大量毛刺
- (MaxPass * MinRt * windows / 1000) < InFlight:判断最大负载是否小于当前实际的负载(即过载了)
- InFlight:表示当前系统中有多少请求
- (MaxPass * MinRt * windows / 1000):表示过去一段时间的最大负载
- MaxPass:表示最近 5s 内,单个采样窗口中最大的请求数
- MinRt:表示最近 5s 内,单个采样窗口中最小的响应时间
- windows:表示一秒内采样窗口的数量,默认配置中是 5s 50 个采样,那么 windows 的值为 10
逻辑总结:
-
第一部分(cpu > 800 OR (Now − PrevDrop) < 1s):
- 只要当前 CPU 利用率过高,或最近刚丢弃过请求(时间小于 1 秒),则满足此条件。
-
第二部分(MaxPass * MinRt * windows / 1000 < InFlight):
- 计算的是系统在该时间窗口内的最大允许处理能力。如果当前的请求数(InFlight)超过了这个能力范围,那么意味着系统可能过载,需要丢弃请求。则满足此条件。
最终,只有当两个条件同时满足时(即整个表达式为 True),才会触发限流逻辑,丢弃当前请求。
这个算法在高并发场景下可以有效地防止系统过载,确保系统的稳定性。
所以,上面这个指标可以解读为:
- CPU超过容忍值,且实时并发量超过系统吞吐量,进入过载逻辑
- CPU未超过容忍值,但是有丢弃记录,且当前时间与上一次丢弃请求的时间差小于1s,且实时并发量超过系统吞吐量,进入过载逻辑 第一种情况较易理解,第二种情况是在CPU未过负载,为了避免限流/恢复机制导致的CPU毛刺而采用了优化策略,其目的是使CPU的负载达到一个相对稳定的水平
压测报告
请求以每秒增加 1 个的速度不停上升,压测效果如下:
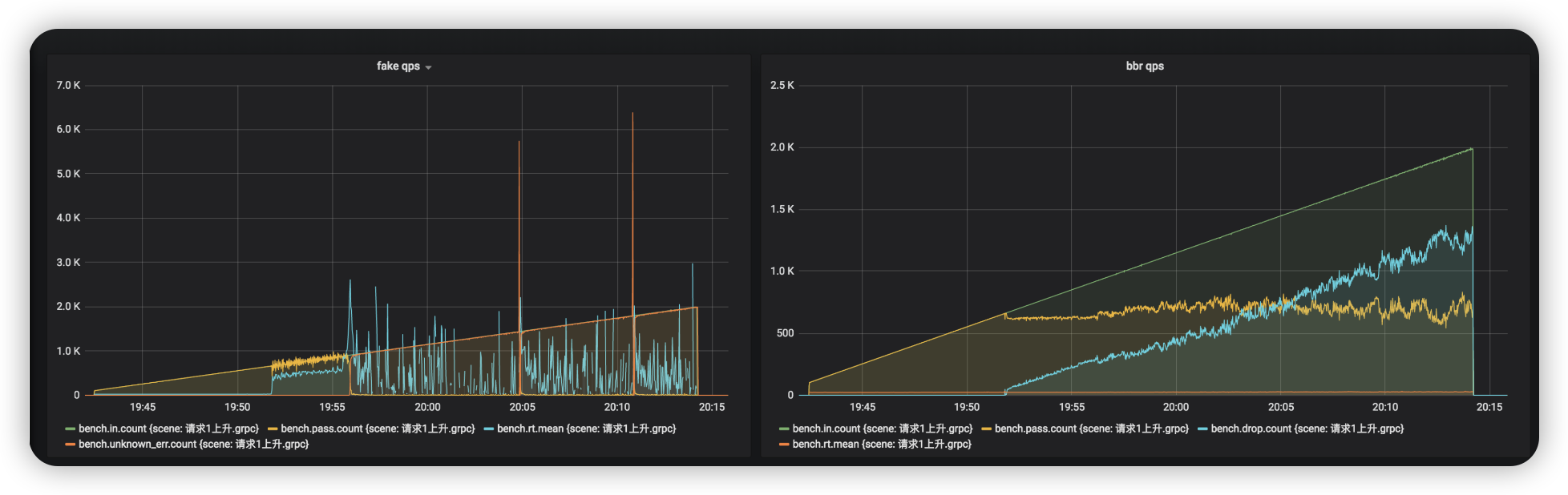 没有限流的场景里,系统在 700qps 时开始抖动,在 1k qps 时被拖垮,几乎没有新的请求能被放行,然而在使用限流之后,系统请求能够稳定在 600 qps 左右,rt 没有暴增,服务也没有被打垮,可见,限流有效的保护了服务。
没有限流的场景里,系统在 700qps 时开始抖动,在 1k qps 时被拖垮,几乎没有新的请求能被放行,然而在使用限流之后,系统请求能够稳定在 600 qps 左右,rt 没有暴增,服务也没有被打垮,可见,限流有效的保护了服务。